Using OpenText Intelligent Classification for Extended ECM Metadata Enrichment
Curriculum
Help & Support
Click here to view a quick video introduction to Product labs.
Click here to view our library of common issues and troubleshooting tips.
Click here to reach out to our support team with your questions.
Overview
In this lab module you will learn how to use OpenText Intelligent Classification to enrich content stored in Extended ECM by auto-populating metadata values using artificial intelligence.
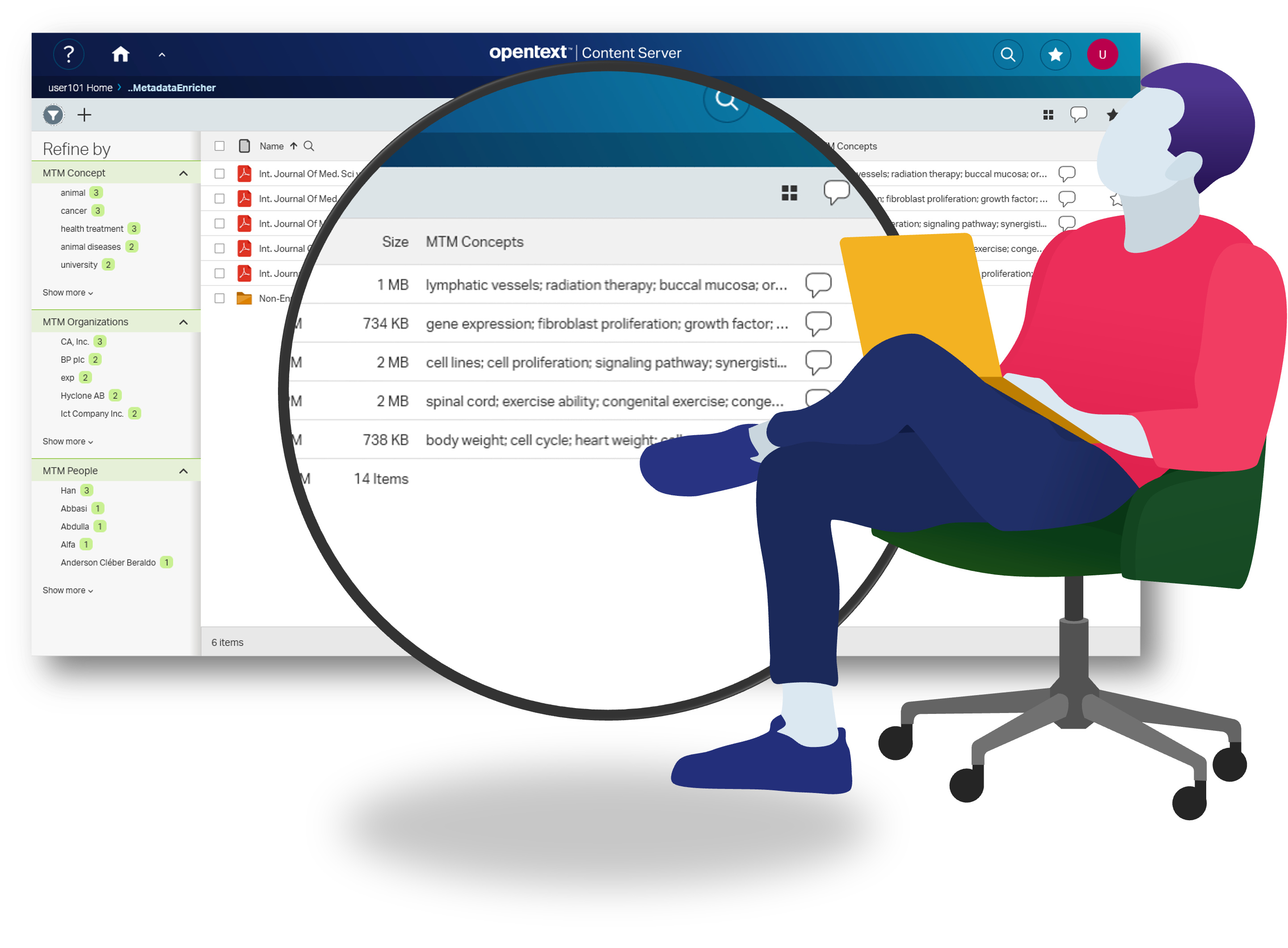
Designed for all users, this introductory lab will let you experience firsthand the powerful combination of OpenText Intelligent Classification and Extended ECM. The text mining engine crawls the document contents in the xECM repository and extracts metadata in the form of categories and attributes like entities, organizations, people and concepts. These results get written back to the xECM and are made available as a faceted search using multiple filters that specify the different aspects and qualities of the documents being searched for. This lab uses content metadata enrichment with xECM, but it can also be used with Documentum and any other ECM repository.
On completion of this course, participants should be able to:
- Automatically enrich a set of documents in Extended ECM with metadata derived from a text mining process
- Perform a multi-faceted search on a set of documents in Extended ECM using newly discovered categories and attributes obtained from the document contents.
- Understand how this solution improves document search capabilities, classification verification and compliance standards adherence.
Firefox or Chrome browser